
Verinin akıl almayacak derecede önemli olduğu bir çağ içerisindeyiz. Hâl böyle olunca yapısal verilerin yanı sıra, kullanıcıların dijital ayak izleri olan; arama-tıklama verileri, otomasyon sistemlerinden üretilen log-sensör verileri ve çok daha çeşitli örneklerden çıkan verinin sağlıklı şekilde tutulması, işlenmesi de oldukça önemli bir hale geliyor.
Geliyordu…
Teknoloji de veri gibi oldukça hızlı büyüyor ve gelişiyor.
Bu kadar büyük veriyi tutabilmek artık eskinin bir problemi olmuşken şu an ise günümüzde bu verilerin gerçek zamanlı analizleri, şirketler için çok önemli kilit bir noktada yer ediniyor.
İşte tam bu anda alet çantamıza Kafka yerleşiyor. Bu yazıda Kafka’nın ne olduğundan, ne için kullanıldığından ve Kafka’nın temel bileşenlerinden bahsedeceğim.
Kafka nedir, ne işe yarar?
Distributed streaming platform.
Apache Kafka, verilerin bir sistemden hızlı bir şekilde toplanıp diğer sistemlere hatasız bir şekilde transferini sağlamak için geliştirilen dağıtık bir veri akış mekanizmasıdır.
Kafka, ne zaman ortaya çıktı?
2011’de Linkedin tarafından geliştirilen Kafka daha sonra Apache çatısı altında açık kaynak bir projeye dönüştürülmüştür.
Kafka, kimler tarafından kullanılıyor?
Günümüzde Linkedin, Netflix, Uber, Twitter gibi çok büyük veriye sahip olan devler tarafından kullanılmakta.
Peki tam olarak ne yapar, hangi dertlere çare bulur bu Kafka?
Şöyle düşünelim;
Elimizde 5 farklı kaynak, 7 farklı hedef olduğunu düşündüğümüzde 35 farklı veri entegrasyonu yapılması gerekir.
Bunlar için farklı bağlantılar kullanılabilir. (TCP, HTTP, REST, FRP, JDBC, ODBC vs.)
Formatlar farklı olabilir. (Binary, JSON, Csv, Avro, Parquet)
Her şeyden önemlisi veri kaynağının üretim hızı hedef kaynağın sindirme hızından çok fazla olabilir.
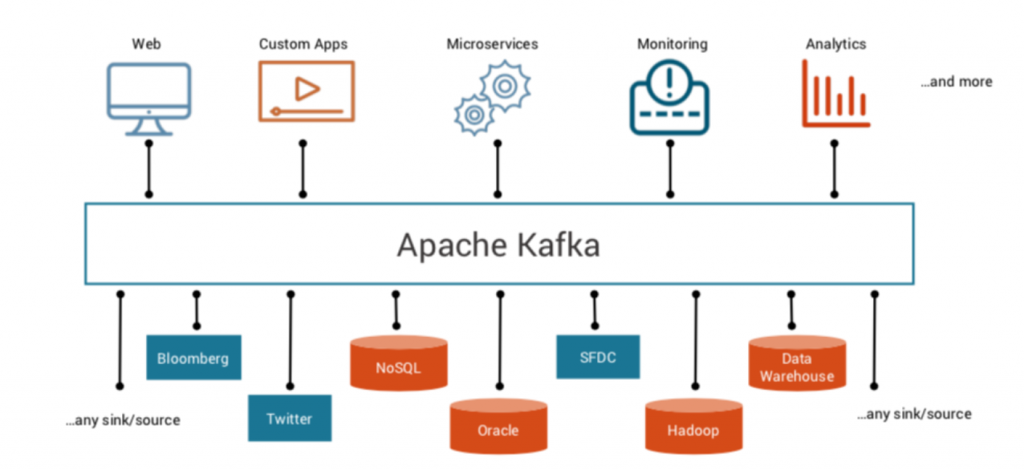
İşte Kafka verilerin bu kaynak sistemlerden, analiz sistemlerine aktarımı için biçilmiş kaftan.
Uygulamaların birbirlerinden asenkron şekilde haberleşmelerini sağlayarak birbirlerine olan bağımlıklıklarını ortadan kaldırır ve üzerlerindeki yüklerini düşürür.
Asenkron: Anında bu bilginin iletilmesine gerek yok, alıcı hazır olduğu zaman bilgiyi alabilir.
Yani özetle;
Kafka, ilişkisel veri tabanlarından, veri ambarlarına, büyük veriden, NoSQL sistemlere kadar birçok veri teknolojileri arasındaki veri akışının protokol ve sistemden bağımsız olarak sorunsuz bir şekilde yapılmasına olanak sağlar.
Üstelik bunu milisaniyeler seviyesinde bir gecikme ile yani gerçek zamanlı olarak yapar.
Kafka ile genel bir bilgilendirme edindiğimize göre temel bileşenlerine geçebiliriz.
Kafka Temel Bileşenleri
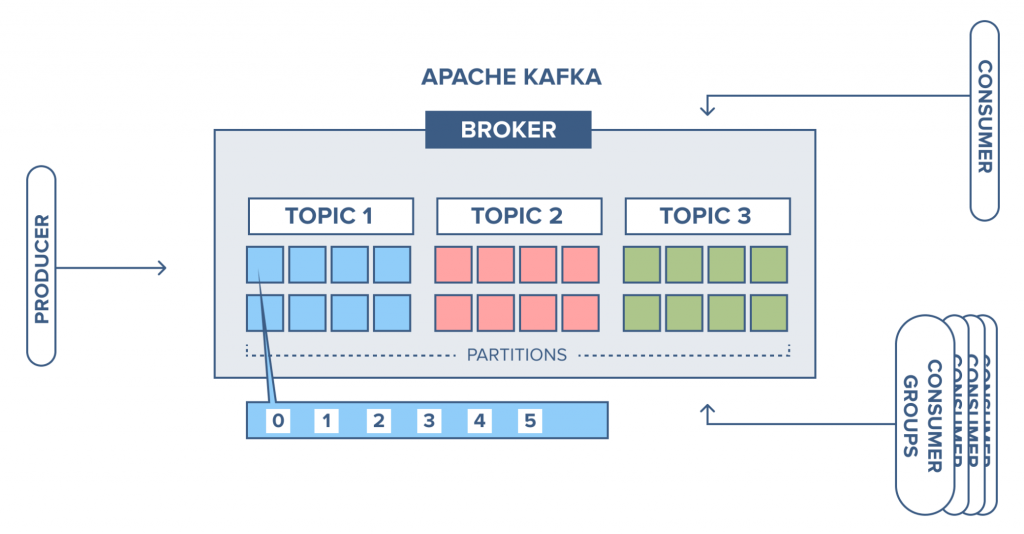
Broker
Kafka Cluster halinde çalışır ve yatay ölçeklenebilirdir.
Broker’lar da Kafka Clusterları oluşturan sunuculardır. Her Broker birer sayıdan oluşan ID ile tanımlıdır.
Kafka dağıtık bir yapıda olduğu için tek bir broker Topic’in tamamını alamaz, belirli partitionları alır.
Topic
Topic, verilerin – mesajların gönderilip alındığı, kullanıcı tanımlı kategori ismidir.
İlişkisel veritabanlarındaki tablolara benzetebiliriz, bir Kafka Cluster içerisinde binlerce topic olabilir.
Bir topic oluştururken içerisindeki Partition ve Replication Factor sayısını belirtiriz.
💡 Kafka bir veritabanı değildir, veriler sınırlı zamanda hataya dayanıklı bir şekilde saklanır, varsayılan süre bir haftadır.
Partition
Tüm veriyi tek bir dosyadan okumaktansa farklı dosyalardan okumak hem daha performanslı hem de hataya karşı daha töleranslı.
Bu sebeple topicler bir veya birden fazla bölümden (Partition) meydana gelirler. Partition sayısına topic oluşturulurken karar verilir, sonradan ihtiyaca göre değiştirilebilir.
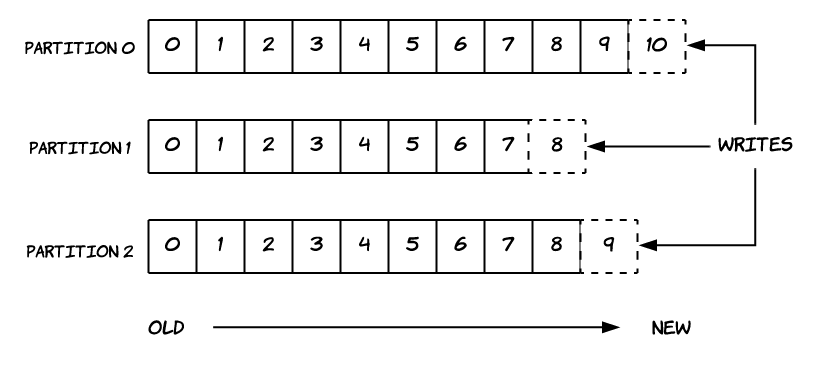
Mesajlar partition içerisine sıralı ve değiştirilemez olarak eklenirler. Artan şekilde bir id alırlar, buna offset denir.
Yani kafkaya gelen her mesajın partition numarası ve offset numarası oluşur.
Partition’lar kendi içinde sıralıdır.
Aşağıdaki görselde Partition 2 için 7. offset’deki veri 8. offset’den önce yazılmıştır.
Fakt Partition 1’deki 5. offset’deki veri ile Partition 2’deki 5. offset’deki veriyi karşılaştıramayız.
💡 Topiclerin bu partition özelliği sayesinde yazma ve okuma işlemleri paralel bir şekilde yapılabilir.
Producer
Kafkaya mesaj gönderen uygulama
Burada mesaj: Bir tablo ya da metin dosyasının bir satırı olarak düşünülebilir.
Topice mesaj gönderirken key ve value göndermek mümkündür. Eğer key atanırsa, aynı keye sahip mesajlar aynı partitiona gönderilir.
Eğer key atanmazsa mesaj topic içerisinde rastgele bir partitiona eklenir.
💡 Örneğin bir operatör şirketi bir müşteriye ait tüm baz istasyonu loglarını aynı partitionda görmek istiyor, bunun için ne yapılması gerekir?
Kafkaya Müşteri ID sini key olarak göndermeli.
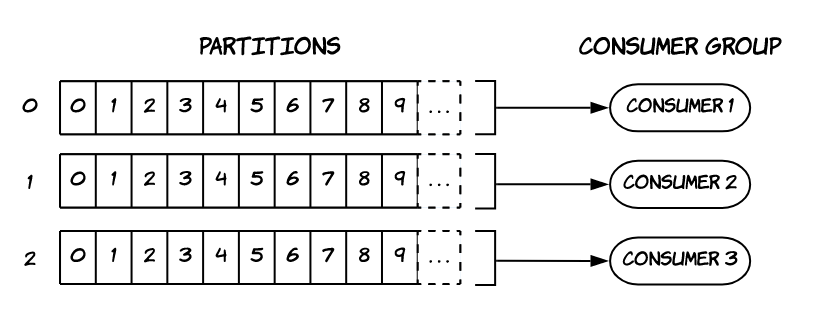
Consumer – Consumer Group
Topic’lerdeki veriyi okurlar.
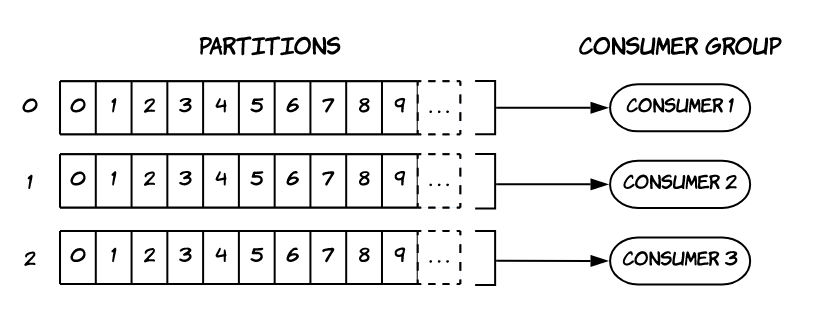
Consumerlar aynı Partition içerisindeki mesajları sıralı bir şekilde okur.
Consumer’lar verileri Consumer Grouplar halinde okur. Tek de olsa her consumer’ın bir grubu vardır. Kullanıcı tarafından grup oluşturulmazsa Kafka bunu otomatik oluşturur.
Bir Consumer Group birden fazla Partition’dan okuyabilir.
Bir Partition’ı ise bir Consumer Group içerisinde sadece bir consumer okuyabilir.
Gruptaki her consumer belli partition’lardan okuma yapar. Mesela topicte 3 partition varsa:
- 3 consumer durumu: Her consumer birer partition’dan okuma yapar.
- 2 consumer durumu: Biri tek partition’dan, biri kalan iki partition’dan okuma yapar.
- 4 consumer durumu: Üçü birer partition’dan okuma yapar. Kalan deaktif olur.
Gruptaki bir consumer’ın çökmesi gibi durumlara karşı bazı durumlarda partition sayısından fazla consumer kullanılabilir.
💡 Bir mesaja erişebilmek için Topic, Partition, Offset bilgilerini bilmek gerekiyor.
💡 Kendisine bırakılan mesajı olduğu gibi iletir, değiştirmez.
💡 Mesaj okuma işleminden sonra kaybolmaz, tekrar erişim mümkündür.
Fault Tolerance (Hataya Karşı Dayanıklılık)
Dağıtık sistem mimarisinin en önemli avantajlarından birisi hataya karşı dayanıklılık. Sunucuların birisinin başına bir şey gelse bile replicalar (kopya) sayesinde sistem sürdürülebilir durumdadır.
Kafka’da da replica’lar sayesinde sistemin devam etmesi ve veri kaybının önüne geçilmesi sağlanır.
Replication ile Topic’lerin her Partition’u birden fazla sunucuda saklanır. Bu sunuculardan biri leader’dir, diğerleri ise kopyasıdır.
Veri alışverişi leader üzerinden sağlanır.
Replication’lar topic oluşturulurken replication-factor parametresi ile belirtilir. Partitions’a uygulanır.
Replication Factor sayısı broker sayısından fazla olamaz.
Leader Replicayı Kafka 3.0 Sürümünün öncesine kadar Zookeeper belirliyordu, fakat Kafka v3.0’ten sonra Kafka’da Zookeeper bağımlılığı kalktı.
💡 Producer sadece Leader Replica ile muhatap olur.
Tüm bu bileşenleriyle Kafka büyük bir soruna derman olmakta, ve çok fazla şirket tarafından tercih edilmekte.
Kafka ile ilgili uygulama çözümleri için kaynaklarda belirteceğim Miuul Data Engineer Pathe göz atabilirsiniz.
Bu yazımda Kafka’nın ne olduğundan hangi amaçla, kimler tarafından kullanıldığından ve temel bileşenlerinden bahsettik.
Gelecek yazılarda görüşmek dileğiyle, sağlıcakla!
Kaynaklar:
https://www.veribilimiokulu.com/apache-kafka-temel-kavramlar
https://kafka.apache.org/documentation.html


